Efficiently Implementing Python Objects With Maps
As could be foreseen by my Call for Memory Benchmarks post a while ago, I am currently working on improving the memory behaviour of PyPy's Python interpreter. In this blog post I want to describe the various data a Python instance can store. Then I want to describe how a branch that I did and that was recently merged implements the various features of instances in a very memory-efficient way.
Python's Object Model
All "normal" new-style Python instances (i.e. instances of subclasses of object without added declarations) store two (or possibly three) kinds of information.
Storing the Class
Every instance knows which class it belongs to. This information is accessible via the .__class__ attribute. It can also be changed to other (compatible enough) classes by writing to that attribute.
Instance Variables
Every instance also has an arbitrary number of attributes stored (also called instance variables). The instance variables used can vary per instance, which is not the case in most other class-based languages: traditionally (e.g. in Smalltalk or Java) the class describes the shape of its instances, which means that the set of admissible instance variable names is the same for all instances of a class.
In Python on the other hand, it is possible to add arbitrary attributes to an instance at any point. The instance behaves like a dictionary mapping attribute names (as strings) to the attribute values.
This is actually how CPython implements instances. Every instance has a reference to a dictionary that stores all the attributes of the instance. This dictionary can be reached via the .__dict__ attribute. To make things more fun, the dictionary can also be changed by writing to that attribute.
Example
As an example, consider the following code:
class A(object):
pass
instance1 = A()
instance1.x = 4
instance1.y = 6
instance1.z = -1
instance2 = A()
instance2.x = 1
instance2.y = 2
instance2.z = 3
These two instances would look something like this in memory:

(The picture glosses over a number of details, but it still shows the essential issues.)
This way of storing things is simple, but unfortunately rather inefficient. Most instances of the same class have the same shape, i.e. the same set of instance attribute names. That means that the key part of all the dictionaries is identical (shown grey here). Therefore storing that part repeatedly in all instances is a waste. In addition, dictionaries are themselves rather large. Since they are typically implemented as hashmaps, which must not be too full to be efficient, a dictionary will use something like 6 words on average per key.
Slots
Since normal instances are rather large, CPython 2.2 introduced slots, to make instances consume less memory. Slots are a way to fix the set of attributes an instance can have. This is achieved by adding a declaration to a class, like this:
class B(object):
__slots__ = ["x", "y", "z"]
Now the instances of B can only have x, y and z as attributes and don't have a dictionary at all. Instead, the instances of B get allocated with enough size to hold exactly the number of instance variables that the class permits. This clearly saves a lot of memory over the dictionary approach, but has a number of disadvantages. It is obviously less flexible, as you cannot add additional instance variables to an instance if you happen to need to do that. It also introduces a set of rules and corner-cases that can be surprising sometimes (e.g. instances of a subclass of a class with slots that doesn't have a slots declaration will have a dict).
Using Maps for Memory-Efficient Instances
As we have seen in the diagram above, the dictionaries of instances of the same class tend to look very similar and share all the keys. The central idea to use less memory is to "factor out" the common parts of the instance dictionaries into a new object, called a "map" (because it is a guide to the landscape of the object, or something). After that factoring out, the representation of the instances above looks something like this:

Every instance now has a reference to its map, which describes what the instance looks like. The actual instance variables are stored in an array (called storage in the diagram). In the example here, the map describes that the instances have three attributes x, y and z. The numbers after the attributes are indexes into the storage array.
If somebody adds a new attribute to one of the instances, the map for that instance will be changed to another map that also contains the new attribute, and the storage will have to grow a field with the new attribute. The maps are immutable, immortal and reused as much as possible. This means, that two instances of the same class with the same set of attributes will have the same map. This also means that the memory the map itself uses is not too important, because it will potentially be amortized over many instances.
Note that using maps makes instances nearly as small as if the correct slots had been declared in the class. The only overhead needed is the indirection to the storage array, because you can get new instance variables, but not new slots.
The concept of a "map" that describes instances is kind of old and comes from the virtual machine for the Self programming language. The optimization was first described in 1989 in a paper by Chambers, Ungar and Lee with the title An Efficient Implementation of Self, a Dynamically-Typed Object-Oriented Language Based on Prototypes. A similar technique is used in Google's V8 JavaScript engine, where the maps are called hidden classes and in the Rhino JavaScript engine.
The rest of the post describes a number of further details that occur if instances are implemented using maps.
Supporting Dictionaries with Maps
The default instance representation with maps as shown above works without actually having a dictionary as part of each instance. If a dictionary is actually requested, by accessing the .__dict__ attribute, it needs to be created and cached. The dictionary is not a normal Python dictionary, but a thin wrapper around the object that forwards all operations to it. From the user's point of view it behaves like a normal dictionary though (it even has the correct type).
The dictionary needs to be cached, because accessing .__dict__ several times should always return the same dictionary. The caching happens by using a different map that knows about the dictionary and putting the dictionary into the storage array:

Things become really complex if the fake dict is used in strange ways. As long as the keys are strings, everything is fine. If somebody adds other keys to the dict, they cannot be represented by the map any more (which supports only attributes, i.e. string keys in the __dict__). If that happens, all the information of the instance will move into the fake dictionary, like this:
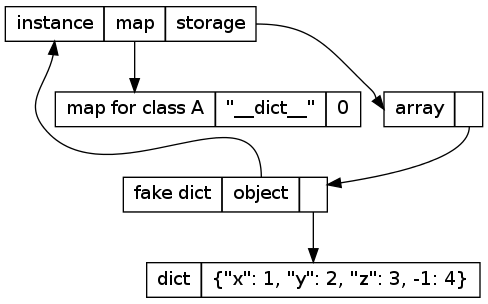
In this picture, the key -1 was added to the instance's dictionary. Since using the dictionary in arbitrary ways should be rare, we are fine with the additional time and memory that the approach takes.
Slots and Maps
Maps work perfectly together with slots, because the slots can just be stored into the storage array used by the maps as well (in practise there are some refinements to that scheme). This means that putting a __slots__ on a class has mostly no effect, because the instance only stores the values of the attributes (and not the names), which is equivalent to the way slots are stored in CPython.
Implementation Details
In the diagrams above, I represented the maps as flat objects. In practise this is a bit more complex, because it needs to be efficient to go from one map to the next when new attributes are added. Thus the maps are organized in a tree.
The instances with their maps from above look a bit more like this in practise:

Every map just describes one attribute of the object, with a name and a an index. Every map also has a back field, that points to another map describing what the rest of the object looks like. This chain ends with a terminator, which also stores the class of the object.
The maps also contain the information necessary for making a new object of class A. Immediately after the new object has been created, its map is the terminator. If the x attribute is added, its maps is changed to the second-lowest map, and so on. The blue arrows show the sequence of maps that the new object goes through when the attributes x, y, z are added.
This representation of maps as chains of objects sounds very inefficient if an object has many attributes. The whole chain has to be walked to find the index. This is true to some extent. The problem goes away in the presence of the JIT, which knows that the chain of maps is an immutable structure, and will thus optimize away all the chain-walking. If the JIT is not used, there are a few caches that try to speed up the walking of this chain (similar to the method cache in CPython and PyPy).
Results
It's hard to compare the improvements of this optimization in a fair way, as the trade-offs are just very different. Just to give an impression, a million objects of the same class with three fields on a 32bit system takes:
without slots:
- 182 MiB memory in CPython
- 177 MiB memory in PyPy without maps
- 40 MiB memory in PyPy with maps
with slots:
- 45 MiB memory in CPython
- 50 MiB memory in PyPy without maps
- 40 MiB memory in PyPy with maps
Note how maps make the objects a bit more efficient like CPython using slots. Also, using slots has no additional effect in PyPy.
Conclusion
Maps are a powerful approach to shrinking the memory used by many similar instances. I think they can be pushed even further (e.g. by adding information about the types of the attributes) and plan to do so in the following months. Details will be forthcoming.
Comments
Not sure if you are glossing over this, but it seems trivial to avoid the map chain walking by duplicating all of the information in a maps back pointer chain into the map itself. However, the lookup keys are still strings, so your options are some kind of frozen hashtable (which could be nice) or a sorted array.
Both of those still seem much more efficient than chasing pointers.
What about the additional running time overhead?
I was surprised not to see any real-world benchmarks (since you collected them earlier). That leaves the impression, that it might be disapointing (knowing that the object/class ratio generally isn't very large).
@Reid:
I am glossing over the runtime overhead, because the JIT completely removes it, as it knows that the maps are immutable. So you only have a problem if you don't want a JIT, in which case maps indeed make some things a bit slower. Duplicating the information everywhere is possible, but I would like to avoid it (we had a prototype that did it, and it became messy quickly).
@Erez
There is no additional runtime overhead if you have the JIT – in fact, things become faster, because the JIT can turn an attribute access into a array field read out of the storage array at a fixed offset.
@Anonymous
I have not presented any real-world benchmarks, because I actually did not get around to running them. Yes, I collected some and started writing a memory benchmark framework. But I didn't have time for a full analysis yet. I plan to do such an analysis hopefully soon.
Anyway, maps never make anything larger, so it is really just a matter of how many instances there are in practice. This will just depend on the benchmark.
Does this optimization enable building pypy using pypy without having 16GB of ram?
Is there anything intrinsic toPyPy in this, or can this optimisation be used in CPython as well?
To remove the chain-walking overhead when the code is not JITted, would it be possible to use a persistent hashtable, like for example the hash trie used in Clojure (see https://blog.higher-order.net/2009/09/08/understanding-clojures-persistenthashmap-deftwice/)? They are quite simple to implement and very fast (almost as fast as a normal hashtable lookup)
ot: i'm part way to implementing that for Python.
https://bazaar.launchpad.net/~washort/%2Bjunk/perseus/annotate/head:/perseus/__init__.py
@Allen: interesting, I wonder how much code would need to be changed to make it RPython...
What are the pypy "with slots" and "without slots" numbers? They are different even though you point out that they have no effect. Is the pypy in question one with sharing dicts?
@verte mapdicts help pypy objects with or without slots (although much more for the latter). There is no difference in pypy with mapdict between having slots or not having slots.
@Zeev no, the translation results from last week already included this optimization. Maps don't help translation much, because we already added all the necessary slot declarations to save memory on CPython.
@ot Would be possible, yes. Not sure it is worth it, given that the total set of attributes of typical instances is not very large. The data structure looks interesting though.
@Carl: yes, it was just hypotetic, "if it is a bottleneck". I think anyway that even with very small instance dictionaries there could be a benefit: most keys would be resolved within the first layer of the trie, so with a single lookup or two at most. But it could be premature optimization.
I still don't understand. Was there a difference with __slots__ on pypy before mapdict? Why are the numbers different on pypy without mapdict? Are those the numbers with or without the old sharing dictimpl? If without, what is the memory usage with sharing dicts?
This came up on StackOverflow, but let me answer it here.
While the CPython split-dict implementation in 3.3+ (PEP 412) may be inspired by your design, it's not the same, and it doesn't provide nearly as much savings.
The first difference is that it still has a full dict struct in the instance. For classes without that many attributes (i.e., most of them), the dict struct is almost as big as the hash table, so this means you typically only get half the savings as in PyPy. However, this means the thing you can access by __dict__ isn't created dynamically, it acts exactly like a dict even at the C API level, and it can transparently (again, even at the C API level) convert itself to a combined dict if needed (if the table needs to expand and there's more than one reference to the shared key table). The fact that the difference between 3.2 and 3.3 is completely undetectable to any code that doesn't directly access the hash buckets is a big part of the reason Mark Shannon was able to get everyone to agree to accept it, and as far as I know there's no serious consideration for changing it.
The second difference is that the dict struct's array is kept in the same (sparse) order as the shared key table, rather than being a compact array indexed by the values of the shared key table. This means it's kept at least 1/3rd unloaded, meaning that again you get less space savings than with PyPy. There's less of a good rationale here; there's a small performance cost to the slightly more complicated code needed for indexing PyPy-style, and it would make small combined dicts one word larger (which could affect classes whose instances all have different attributes, or cases where you have a huge number of classes with few instances, or other edge cases). The PEP implies that using the sparse implementation is probably overly conservative, and leaves open the possibility of changing it after 3.3.